ChatGPT shipped GPT-5.5 last week. It’s the new “smartest” model OpenAI has released, with new pricing, a 1M token context window in the API, and a positioning push around agentic, multi-step work.
I wanted to know what most brands actually care about: does it cite different sources than GPT-5.4? Does it search the web differently? And what should brands change about their AI visibility strategy now that the new default Thinking model is here?
We ran 50 prompts through GPT-5.5 Thinking, GPT-5.4 Thinking, and GPT-5.3 Instant. 150 conversations. 1,821 fan-out queries. 11,469 web search results. 1,257 citations.
Here’s the short version: GPT-5.5 cites your brand 47% of the time, down from 57% on GPT-5.4. But the average hides a 26-percentage-point swing by category. The mechanism is one specific behavioral change that nobody’s talking about: GPT-5.4 used Google’s site: operator on 40.5% of its searches. GPT-5.5 dropped that to 12.6%.
Here’s the long version.
How we did this
We, at Writesonic, ran 50 prompts on ChatGPT across three models: GPT-5.5 Thinking (the new premium), GPT-5.4 Thinking (the previous premium), and GPT-5.3 Instant (the current default). That’s 150 total conversations, run on April 27, 2026 from a single ChatGPT Plus account in the US.
After each response, we pulled the full conversation payload via ChatGPT’s internal API. That gave us every fan-out query the model issued, every web result returned to it, and every URL it cited in its final answer. We also verified the model_slug on each conversation to make sure ChatGPT’s UI didn’t silently swap models on us.
We classified every cited URL as first-party (the brand the user asked about) or third-party (review sites, blogs, Reddit, retailers, media) using Claude Haiku 4.5 with detailed instructions and 50+ in-prompt examples. As a calibration check, GPT-5.4’s first-party rate came out at 56.8%, in line with the 56% we measured in our previous study.
We also ran 30 of these prompts through Google US and Bing US via SerpAPI to compare ChatGPT’s citation choices against traditional search rankings.
| What we measured | Count |
|---|---|
| Total conversations | 150 |
| Fan-out queries extracted | 1,821 |
| Web search results returned | 11,469 |
| Citations classified | 1,257 |
| Response words reviewed | ~88,650 |
| SerpAPI queries (Google + Bing) | 60 |
Now, here’s what we found.
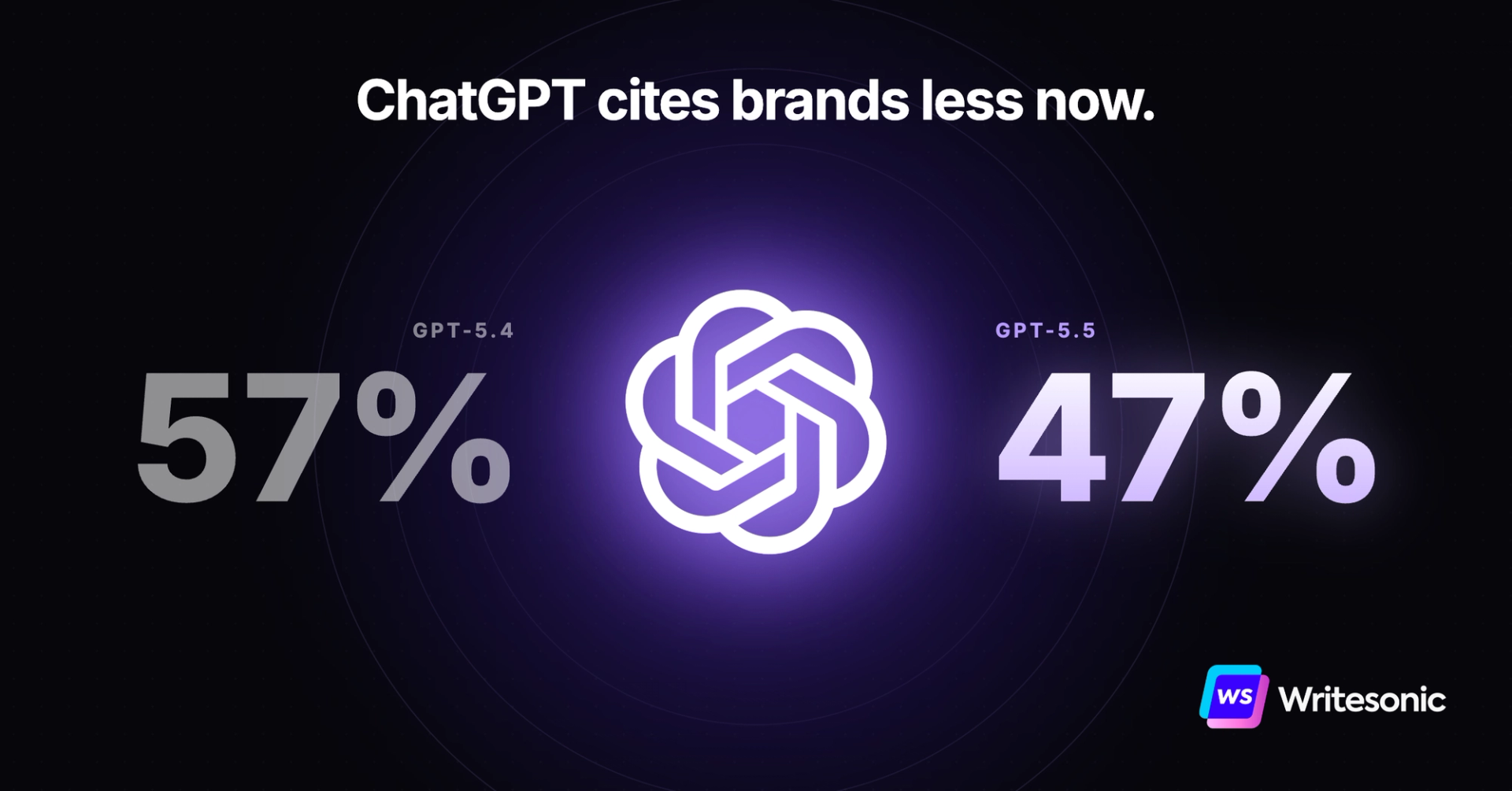
GPT-5.5 cites brands 10pp less than GPT-5.4. But still 4x more than GPT-5.3.
This is the headline finding.
GPT-5.5 cited brand websites 47.2% of the time. GPT-5.4 cited them 56.8%. GPT-5.3 cited them 13.4%.
GPT-5.3 → 5.4 was a phase change. GPT-5.4 → 5.5 is a calibration. Same direction, smaller magnitude. The new Thinking model is still dramatically more brand-forward than the default Instant model, just less aggressively so than its predecessor.
But the average is misleading. We’ll get to why.
The two models cite mostly the same source pool, with shifts at the margin
A natural question: did GPT-5.5 swap out GPT-5.4’s source pool for a new one?
No. The Jaccard overlap on cited domains tells the story:
| Comparison | Domain overlap |
|---|---|
| 5.3 Instant ↔ 5.4 Thinking | 6.2% (essentially different worlds) |
| 5.3 Instant ↔ 5.5 Thinking | 7.0% (5.5 didn’t return to 5.3) |
| 5.4 Thinking ↔ 5.5 Thinking | 28.9% (5.5 stays in 5.4’s family) |
GPT-5.5 isn’t reverting to GPT-5.3 behavior. It’s adjusting GPT-5.4’s behavior at the margin. Same source pool, different selection within it.
The pattern holds across most prompts, but with category exceptions
Out of 50 prompts, GPT-5.5’s first-party rate was within ±10pp of GPT-5.4’s on 28 prompts. The other 22 saw bigger swings, and the swings split sharply by category.
Categories where GPT-5.5 cites brands much less than GPT-5.4:
| Category | 5.4 first-party | 5.5 first-party | Δ |
|---|---|---|---|
| Services | 83% | 19% | −65pp |
| Legal | 84% | 29% | −56pp |
| Education | 97% | 56% | −41pp |
| Marketing | 86% | 55% | −31pp |
| Food | 38% | 12% | −26pp |
| Healthcare | 52% | 28% | −24pp |
And categories where GPT-5.5 cites brands more than GPT-5.4:
| Category | 5.4 first-party | 5.5 first-party | Δ |
|---|---|---|---|
| Fitness | 17% | 71% | +55pp |
| Travel | 48% | 74% | +26pp |
| Ecommerce | 14% | 31% | +16pp |
| Trends | 20% | 32% | +11pp |
A 10pp average drop hides 26pp swings the other way. Brands in legal, education, marketing, food, and healthcare are losing ChatGPT visibility under GPT-5.5. Brands in fitness, travel, ecommerce, and trends are gaining it. If your AEO playbook was built on GPT-5.4 averages, your category may be moving in the opposite direction of the headline.
The “kingmaker” sites on GPT-5.5
The most-cited domains across all 50 prompts on GPT-5.5 Thinking:
| Domain | Citations | Type |
|---|---|---|
| manduka.com | 10 | Brand (yoga mats) |
| techradar.com | 8 | Tech reviews |
| reuters.com | 7 | Media |
| g2.com | 6 | Software review aggregator |
| flexispot.com | 6 | Brand (desks) |
| nccih.nih.gov | 5 | Government |
| tomsguide.com | 5 | Tech reviews |
| reviewed.com | 5 | Tech reviews |
| fortune.com | 5 | Media |
| apple.com | 5 | Brand |
| samsung.com | 5 | Brand |
| shopify.com | 4 | Brand |
| bigcommerce.com | 4 | Brand |
| xero.com | 4 | Brand |
Brand pages and review aggregators alternate at the top. That’s exactly the moderate first-party / third-party blend the 47% number describes. For comparison, GPT-5.3 Instant’s top list is dominated by media and retailers: forbes.com (21 citations), walmart.com (12), bestbuy.com (10), techradar.com (9), reddit.com (6).
For brands: GPT-5.5 has reopened the door to review aggregators. G2, TechRadar, Tom’s Guide, Reviewed are partially back in play after being squeezed out under GPT-5.4.
GPT-5.5 sends 30% fewer fan-out queries than GPT-5.4
GPT-5.5 issued 7.3 fan-out queries per prompt on average, down from GPT-5.4’s 10.5. GPT-5.3 issued 1.0, almost always a single search. The total query budget per prompt collapsed by 30% between the two Thinking models.
| Model | Avg fan-outs per prompt | Total fan-outs across 50 prompts |
|---|---|---|
| GPT-5.3 Instant | 1.0 | 49 |
| GPT-5.4 Thinking | 10.5 | 1,047 |
| GPT-5.5 Thinking | 7.3 | 725 |
What GPT-5.5’s fan-out queries actually look like
A typical GPT-5.5 Thinking fan-out for “best CRM for a 50-person B2B SaaS company”:
1. best CRM B2B SaaS company 50 employees 2026 HubSpot Salesforce Pipedrive Attio Close pricing features
2. HubSpot Sales Hub pricing 2026 official
3. Salesforce Sales Cloud pricing 2026 official
4. Pipedrive pricing 2026 officialCompare to a typical GPT-5.4 Thinking fan-out for the same prompt:
1. best CRM 50 person B2B SaaS company 2026
2. HubSpot vs Salesforce vs Pipedrive pricing 2026
3. pricing site:hubspot.com Sales Hub
4. pricing site:salesforce.com Sales Cloud
5. Attio CRM pricing site:attio.com
6. Close.io pricing 2026
7. Zoho CRM pricing 2026
8. Pipedrive vs Close vs HubSpot small business CRMGPT-5.4 was visibly running broader, more aggressive scoping queries, often using site: to force a result onto the brand domain. GPT-5.5’s queries are tighter and rarely use that operator.
Same search index, different query strategy
ChatGPT is presumed to use Bing as its underlying search index. The data makes clear that what’s changed between models isn’t the index. It’s the model’s strategy for querying that index. GPT-5.4 issues many more queries, scopes them aggressively, and reaches into specific brand domains. GPT-5.5 issues fewer queries, scopes them less, and lets the search engine return a more natural mix of results.
GPT-5.5 cuts the site: operator that defined GPT-5.4
This is the single biggest behavioral change between the two Thinking models, and the most plausible mechanistic cause of every other delta we measured.
| Model | Total fan-outs | Used site: operator | site: % |
|---|---|---|---|
| GPT-5.5 Thinking | 725 | 91 | 12.6% |
| GPT-5.4 Thinking | 1,047 | 424 | 40.5% |
| GPT-5.3 Instant | 49 | 0 | 0% |
GPT-5.4 issued site: operator queries on 40.5% of all fan-outs. That’s Google’s domain-restriction operator, used to force results onto specific brand sites (pricing site:hubspot.com, reviews site:expedia.com). GPT-5.5 does this on only 12.6% of fan-outs. A 3.2x reduction. GPT-5.3 never uses site: at all.
The downstream effects are visible everywhere:
- Without forced domain scoping, the model lands on a more natural mix of pages. First-party citation rate drops 10pp.
- It runs fewer total queries. Fan-outs drop 30%.
- It reaches fewer brand product pages. Final-answer citations drop 23%.
Top site: targets per Thinking model:
- GPT-5.4 Thinking: expedia.com, polestar.com, hotels.com, fueleconomy.gov, roamresearch.com, linear.app, shopify.com, bigcommerce.com (12
site:queries each, sometimes more). A clear pattern of systematic data extraction from named brand domains. - GPT-5.5 Thinking: hubspot.com (6×), bigcommerce.com (4×), zoom.us (4×), garmin.com (4×), quickbooks.intuit.com (4×). A meaningfully smaller, narrower set.
For brands and AEO operators, this is the most actionable shift in the dataset. Strategies that relied on site:-style scoping landing your domain in ChatGPT answers are 3x less likely to fire under GPT-5.5.
GPT-5.5 cites pricing pages 21% less than GPT-5.4
Pricing-page citations are the cleanest signal of brand-direct intent in ChatGPT answers. Both Thinking models cite them. GPT-5.5 cites them less.
| Model | Pricing-page citations | % of all citations |
|---|---|---|
| GPT-5.3 Instant | 0 | 0% |
| GPT-5.4 Thinking | 52 | 11.1% |
| GPT-5.5 Thinking | 32 | 8.8% |
GPT-5.3 cited zero pricing pages across 425 total citations. It doesn’t reach into brand pricing structures at all. GPT-5.4 made pricing pages 11% of all its citations. GPT-5.5 dialed that to 8.8%, a 21% reduction.
The drop tracks the site: operator drop almost exactly. Most of GPT-5.4’s pricing-page citations came from site: queries forcing the search onto the brand domain. Take the operator away and the pricing-page citations follow it down.
Pricing pages still punch above their weight. They’re 8.8% of GPT-5.5’s citations despite being a tiny fraction of any brand’s content footprint. They still pull more AI visibility per page than anything else on your site. Just not as overrepresented as they were under GPT-5.4.
Both Thinking models bypass Google rankings. GPT-5.5 just slightly less.
We ran 30 prompts through Google US and Bing US via SerpAPI and checked whether each model’s cited domains for the same prompt also appeared in the search engine’s top 10 organic results.
| Model | Cited × prompt pairs | In Google top 10 | In Bing top 10 | In either | Absent from both |
|---|---|---|---|---|---|
| GPT-5.3 Instant | 179 | 30% | 7% | 31% | 69% |
| GPT-5.4 Thinking | 143 | 13% | 2% | 13% | 87% |
| GPT-5.5 Thinking | 140 | 16% | 3% | 16% | 84% |
GPT-5.4 routes users to a domain set where 87% of the picks aren’t even in Google’s top 10 for the same query. GPT-5.5 stays in that regime. Both Thinking models effectively operate as their own answer engines, not as wrappers over Bing.
The 3pp uptick from GPT-5.4 (13%) to GPT-5.5 (16%) on Google overlap is small but directionally consistent with the rest of the picture: less site: scoping, slightly less brand bias, slightly more “Google-rankable” sources.
GPT-5.3 is a different story
GPT-5.3 Instant looks much more like a thin wrapper over conventional search. 30% of its cited domains do appear in Google’s top 10. Roughly double GPT-5.4’s overlap, almost double GPT-5.5’s.
For brands, that means SEO investment translates to ChatGPT visibility under GPT-5.3 in a way it largely doesn’t under either Thinking model. Most ChatGPT users are still on GPT-5.3 Instant by default. Your Google rankings still matter for that audience.
GPT-5.5 makes AI search attribution slightly less trackable
Both Thinking models include utm_source=chatgpt.com (and sometimes utm_medium=src) tracking parameters on cited URLs. Brands can isolate ChatGPT-driven traffic in their analytics with no instrumentation work.
The coverage rates:
| Model | Citations carrying utm_source=chatgpt.com |
|---|---|
| GPT-5.3 Instant | 92% |
| GPT-5.4 Thinking | 89% |
| GPT-5.5 Thinking | 82% |
GPT-5.5 covers fewer of its citations with UTM tagging than GPT-5.4 does (82% vs 89%). It’s a small drop, but enough that brands relying on UTM-only attribution will see slightly less ChatGPT traffic show up tagged. For complete attribution, pair UTM tracking with referrer-based detection in GA4.
Some prompts don’t trigger web search at all
Search is now near-universal across all three model tiers, but not literally universal.
| Model | Conversations without web search | % |
|---|---|---|
| GPT-5.3 Instant | 1 | 2% |
| GPT-5.4 Thinking | 3 | 6% |
| GPT-5.5 Thinking | 3 | 6% |
The handful of conversations that didn’t trigger search were a mix of trend-style prompts (“biggest ecommerce trends for 2026”) and educational prompts where the model judged its training data sufficient. For practical purposes, brands should assume any prompt in their category will trigger a web search regardless of which ChatGPT tier the user is on.
Shopping intent is mostly unchanged on GPT-5.5
The five shopping-intent prompts in the set stayed roughly flat between Thinking models:
- “I want to buy wireless earbuds under $150 for running, what should I get?”
- “Where can I buy the cheapest MacBook Air M4 right now?”
- “Best deals on standing desks this week”
- “I need to buy a gift for my wife under $100, what are good options?”
- “Buy the best rated espresso machine under $500”
| Model | First-party rate on shopping prompts |
|---|---|
| GPT-5.3 Instant | 33.8% |
| GPT-5.4 Thinking | 37.2% |
| GPT-5.5 Thinking | 35.1% |
The category where you’d most expect retailer (Walmart, BestBuy, Amazon) and brand (JBL, Sony, Apple) competition is also the most stable across model tiers. For any DTC brand, the 5.4 → 5.5 shift won’t show up on shopping prompts. It’ll show up on informational and recommendation prompts.
GPT-5.5 surfaces fresher content than GPT-5.4
We computed each cited URL’s age relative to the conversation timestamp using the pub_date metadata returned in ChatGPT’s search results.
| Model | Cited URLs with pub_date | <30 days old | 30–90 days | 90 days–1 year | >1 year | Median age (days) |
|---|---|---|---|---|---|---|
| GPT-5.5 Thinking | 30% | 28.0% | 22.4% | 32.7% | 16.8% | 88 |
| GPT-5.4 Thinking | 31% | 30.1% | 13.7% | 21.9% | 34.2% | 108 |
GPT-5.5 cites pages that are slightly fresher on the median (88 days vs 108) and noticeably less skewed toward “older than a year” content (16.8% of dated cites vs 34.2% under GPT-5.4). The under-30-days bucket is roughly tied.
The improvement at the median tracks GPT-5.5’s broader, less-scoped query strategy. When you don’t force site:hubspot.com, you don’t end up surfacing the same handful of evergreen pricing/product pages. You see more recent reviews, news, and posts.
GPT-5.3 doesn’t expose pub_date metadata in its search results, so freshness can’t be computed for it.
How to extract fan-out queries from any ChatGPT conversation
If you want to run this kind of analysis on your own prompts, you don’t need any special API access. ChatGPT’s frontend exposes the full data via its internal API, which you can hit directly from a logged-in browser session.
Step 1: Have a ChatGPT conversation
Open chatgpt.com, pick the model you want to analyze using the picker in the chat header, and send your prompt. Wait for the response to finish.
Step 2: Open the console
Cmd + Option + J on Mac. Ctrl + Shift + J on Windows. Switch to the Console tab.
Step 3: Paste this script
const cid = location.pathname.split("/c/")[1];
const session = await (await fetch("/api/auth/session")).json();
const r = await fetch(`/backend-api/conversation/${cid}`, {
headers: { Authorization: `Bearer ${session.accessToken}` },
});
const data = await r.json();
const fanouts = [];
const citations = [];
for (const node of Object.values(data.mapping)) {
const meta = node?.message?.metadata || {};
if (meta.search_model_queries?.queries) fanouts.push(...meta.search_model_queries.queries);
for (const ref of meta.content_references || [])
for (const item of ref.items || []) citations.push(item.url);
}
console.log("Fan-out queries:", [...new Set(fanouts)]);
console.log("Citations:", [...new Set(citations)]);
console.log("Model slug:", Object.values(data.mapping).map(n => n?.message?.metadata?.model_slug).filter(Boolean)[0]);What to look for
The script returns three things:
- Fan-out queries. Every search query the model issued, including any
site:operators. Look forsite:yourbrand.compatterns to see if ChatGPT is force-scoping to your domain. - Citations. Every URL the model linked to in its final answer. Compare these against your own brand domains and your competitors’.
- Model slug. The authoritative model that handled this conversation (
gpt-5-5-thinking,gpt-5-4-thinking,gpt-5-3-instant). Use this to verify you’re actually testing the model you intended.
The full picture: GPT-5.3 to GPT-5.4 to GPT-5.5
| Metric | 5.3 Instant | 5.4 Thinking | 5.5 Thinking | Δ 5.4 → 5.5 |
|---|---|---|---|---|
| First-party citation % | 13.4% | 56.8% | 47.2% | −9.6 pp |
| Avg fan-out queries | 1.0 | 10.5 | 7.3 | −30% |
| site: operator usage | 0% | 40.5% | 12.6% | −3.2× |
| Avg web results read | 12.3 | 114.6 | 102.7 | −10% |
| Avg citations in final answer | 8.5 | 9.4 | 7.2 | −23% |
| Pricing-page citations (% of total) | 0% | 11.1% | 8.8% | −21% |
| Cited domains in Google top 10 | 30% | 13% | 16% | +3 pp |
| Cited domains in Bing top 10 | 7% | 2% | 3% | +1 pp |
| Cited domains absent from both | 69% | 87% | 84% | −3 pp |
| Median cited-page age (days) | n/a | 108 | 88 | fresher |
| Avg response length (words) | 621 | 571 | 581 | +2% |
| Search used (% of convos) | 98% | 94% | 94% | flat |
| utm_source=chatgpt coverage | 92% | 89% | 82% | −7 pp |
GPT-5.3 → GPT-5.4 was a phase change. GPT-5.4 → GPT-5.5 is a calibration along the same axis. Same direction, smaller magnitude, slightly different category mix.
But what about the free tier? Update.
Everything above is about ChatGPT’s Thinking models, the premium tier most AEO professionals track. After publishing this study, we ran the same prompt set through GPT-5.5 Instant, the new free-tier default that handles roughly 90% of consumer ChatGPT queries.
The Instant tier behaves dramatically differently than what we found above:
- Brand citations halved. GPT-5.5 Instant cites brand websites just 6% of the time, down from 13% on GPT-5.3 Instant. For most prompt categories, the rate is exactly 0%.
- Reddit is now ChatGPT’s most-cited domain on Instant. Reddit citations grew 6× from one model version to the next. It’s now the single most-cited domain by a 3× margin over the next-most-cited source.
- 8 of 50 prompts auto-escalate from Instant to Thinking – even with the user’s Auto-switch toggle disabled. The user picked Instant. ChatGPT silently rerouted them to Thinking anyway. Routing is content-based, not random.
The free-tier ChatGPT experience is now a fundamentally different surface than the Thinking-tier experience. Same model generation, almost entirely different cited sources. If you’re auditing ChatGPT visibility for a brand or client, you need to measure both tiers separately.
Read the full GPT-5.5 Instant study →
What this means for brands
1. The site: operator moat is gone. Brands whose ChatGPT visibility under GPT-5.4 came from the model issuing site:yourbrand.com queries should expect 3x fewer of those queries to fire under GPT-5.5. Direct-from-brand citations drop accordingly.
2. Review aggregators are partially back in play. G2, TechRadar, Tom’s Guide, Capterra were squeezed out under GPT-5.4 because the model preferred direct brand sources. Under GPT-5.5, third-party share rises 10pp, and review-site SEO matters again.
3. Category matters more than it did before. The 10pp average drop in first-party rate hides 26pp swings by category. Fitness, travel, and ecommerce brands gain ChatGPT visibility under GPT-5.5. Legal, education, marketing, and food brands lose it. Plan based on your category, not the average.
4. Pricing pages still pull more AI visibility per page than anything else. Even at 8.8%, pricing pages remain disproportionately cited relative to their share of any brand’s content footprint. Make sure yours is up to date, dateable, and indexable.
5. UTM tracking still works, but covers fewer citations. GPT-5.5 tags 82% of citations with utm_source=chatgpt.com, down from 89% on GPT-5.4. For complete attribution, pair UTM detection with referrer-based detection in your analytics.
What this means for agencies
1. Audit by category, not by brand. A SaaS client and a fitness client will see opposite directional shifts under the 5.4 → 5.5 transition. Don’t assume one playbook generalizes.
2. Re-test prompts you tracked under GPT-5.4. ChatGPT’s “Latest” Thinking model is now GPT-5.5. Any client dashboard tracking ChatGPT visibility against a 5.4 baseline is now showing data from a model that behaves measurably differently. Re-run the prompt set against GPT-5.5 explicitly to get a current picture.
3. The console script above lets you build your own measurement loop. No API keys, no scraping, no scale issues for individual brand audits. Just the user’s own browser session, a prompt, and a few lines of console code per measurement.
We built the same analysis pipeline we used for this study into our AI visibility platform. Track your citation share, monitor fan-out queries, and see which models cite your brand, all in one place. See it in action →
Questions we’re still investigating
Run-to-run variability. ChatGPT is non-deterministic. Single-run measurements like this one give directional reads, not statistical certainty. We’re planning a multi-run pass to put confidence intervals around the deltas.
Extended Thinking effort. All Thinking-model conversations here used Standard effort. Whether the same patterns hold under Extended effort is open.
Failure-case deep dives. A few prompts saw GPT-5.5 swing from GPT-5.4 by 50+ percentage points (Services, Legal, Fitness). Reading those conversations side-by-side to understand what triggered each swing would clarify whether the change is in the search strategy or in the answer-shaping step.
What broke the site: habit? GPT-5.4 used site: on 40.5% of fan-outs. GPT-5.5 cut that to 12.6%. Was it a deliberate behavioral training change, or a side effect of the new agentic posture? OpenAI hasn’t said.
Methodology
50 prompts spanning 16 categories, derived from a representative cross-section of consumer and B2B research queries. Each prompt run once per model (150 conversations total) on April 27, 2026 from a single ChatGPT Plus account in the United States.
Conversation payloads pulled directly from ChatGPT’s /backend-api/conversation/<id> endpoint with browser-session authentication. Every payload includes the full message tree, all search_model_queries (fan-outs), all search_result_groups (web results), all content_references (citations), and model_slug per message.
Citation classification: Claude Haiku 4.5 with a detailed system prompt and 50+ in-prompt examples. Each (prompt, URL) pair classified independently as FIRST, THIRD, or UNCLEAR. UNCLEAR labels (7 out of ~910) conservatively counted as third-party. Calibration: GPT-5.4 first-party rate measured at 56.8%, in line with previously observed benchmarks.
Search-engine cross-reference: 30 prompts × Google US + Bing US (top 10 organic results each) via SerpAPI. Domain-level overlap computed against the cited-domain set per (model, prompt).
Limitations: Single user account, single run per prompt, single point in time. Repeat runs may produce different results due to ChatGPT non-determinism. Absolute percentages should be treated as point estimates. Cross-model deltas are more stable.
TLDR
- GPT-5.5 cites brands 47% of the time, down from 57% on GPT-5.4 (still way above 5.3’s 13%).
- The mechanism is
site:operator usage falling from 40.5% of fan-outs to 12.6%. A 3.2x drop. - 30% fewer fan-out queries, 10% fewer pages read, 23% fewer final citations. Response length unchanged.
- Pricing-page citations down 21%. Median cited-page age down from 108 to 88 days.
- Both Thinking models are still ~85% disconnected from Google’s top 10. GPT-5.3 is much closer to Google.
- Category swings are big: fitness, travel, ecommerce gain brand visibility. Legal, education, marketing lose it.
- For brands: the
site:operator moat is gone. Plan for category-specific, not average, shifts.
If your AEO dashboard was calibrated to GPT-5.4, it’s measuring a model that’s no longer ChatGPT’s “Latest” Thinking option. Re-run your prompt set against GPT-5.5 this week, and segment your analysis by category before drawing conclusions. Start with a free Writesonic account, or book a demo to see GPT-5.5 visibility tracking in your dashboard.
Founder @ Writesonic
Samanyou is the founder of Writesonic, a platform that helps you track & boost your brand’s visibility in AI search. Two years before the launch of ChatGPT, Writesonic was already at the forefront, helping organizations automate their entire marketing workflow through specialized AI agents for SEO and content. Samanyou is a Forbes 30 Under 30 awardee and a winner of the 2019 Global Undergraduate Awards, often referred to as the junior Nobel Prize.




