Key Takeaways
- UGC platforms own AI citations. Reddit, Wikipedia, YouTube, LinkedIn, Medium—seven of the top 10 most-cited domains are platforms where users create content, not publishers. You can’t build the next Reddit, but you can optimize your presence on it.
- Two-thirds of domains only appear on one platform. 67.4% of the 2.4M domains we tracked got cited by exactly one AI platform. Just 6.5% achieved universal presence (5-8 platforms).
- URL diversification is structural, not strategic. Reddit has 678,255 unique URLs in our dataset. Wikipedia has 111,823. That diversity comes from millions of users creating content daily. You’re not publishing 678,000 pages, but you can place high-value content where LLMs are already looking.
- Query frames have monopoly winners. Reddit owns alternatives queries, Wikipedia owns “what is,” YouTube and Stack Overflow split how-to by technical depth. G2 and Capterra dominate B2B comparisons. The platforms people trust for specific question types are the platforms LLMs trust too.
- Third-party presence isn’t optional. Owned content establishes your POV, but third-party presence is where citation volume lives. Treating it as a nice-to-have means you’re ignoring where the game is being played.
So far in my foray into LLM data, I’ve focused on content types and query frames. What formats get cited, how platforms respond to different intents, whether branded prompts change citation patterns.
I wanted even more specificity: which domains dominate these citations? Who’s publishing the listicles that LLMs so love to surface? Who owns the reviews that these platforms trust?
I ranked 2.4 million domains by how often they get cited across eight AI platforms. Here’s what the top of the list looks like:
- Wikipedia
- YouTube
- Medium
You can quickly spot the commonalities. These are user-generated content platforms, aggregators. Community spaces where millions of people create millions of pages.
That pattern tells us something important about how LLMs source information—and where the leverage points are for AI visibility.
How I categorized platform strategies
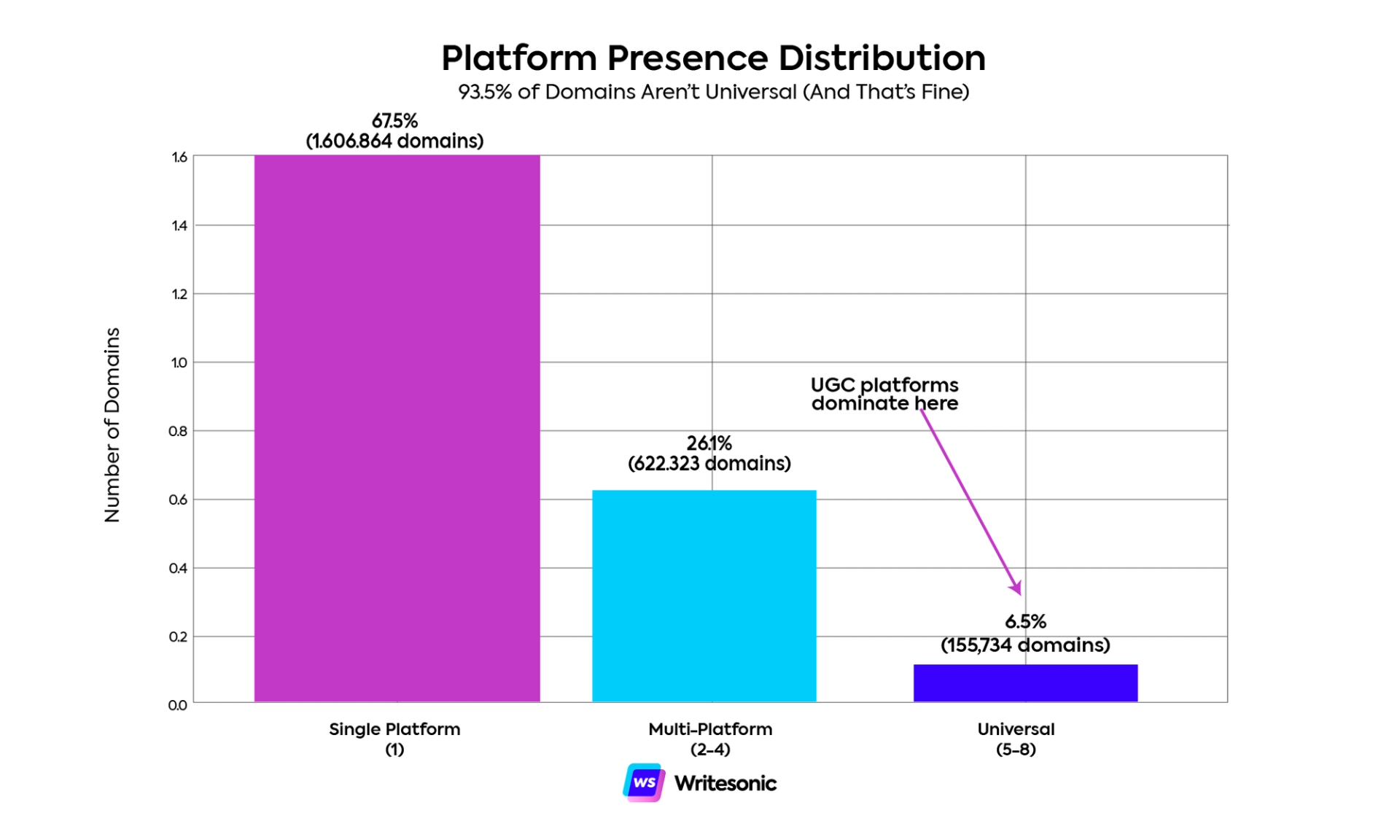
I classified the 2.4 million domains based on how many platforms cited them during the study period (May 2025 to October 2025):
- Universal domains (5-8 platforms): Domains cited by at least five of the eight platforms we tracked. These are the generalists showing up regardless of which AI tool someone uses.
- Multi-platform domains (2-4 platforms): Domains appearing on two to four platforms. They have cross-platform presence but aren’t ubiquitous.
- Single-platform domains (1 platform): Domains cited by a single platform during the study period.
The distribution:
- Universal (5-8 platforms): 155,734 domains (6.5%)
- Multi-platform (2-4): 622,323 domains (26.1%)
- Single-platform (1): 1,606,864 domains (67.4%)
Two-thirds of all cited domains appear on exactly one platform. Just 6.5% achieve universal presence.
Finding #1: Universal domains are UGC aggregators (and you can’t compete with that directly)
Here’s the top 10 list of universal domains by total citations:
- reddit.com – 7,328,267 citations across 7 platforms
- wikipedia.org – 4,289,547 citations across 8 platforms
- youtube.com – 2,661,056 citations across 7 platforms
- google.com – 1,652,610 citations across 8 platforms
- linkedin.com – 1,424,134 citations across 8 platforms
- g2.com – 1,219,726 citations across 8 platforms
- medium.com – 1,157,881 citations across 8 platforms
- forbes.com – 1,155,981 citations across 7 platforms
- nih.gov – 974,124 citations across 8 platforms
- zapier.com – 956,337 citations across 8 platforms
There’s no sidestepping the pattern. Seven of the top 10 are platforms where users create content, not publishers creating their own.
Reddit aggregates community discussions, Wikipedia aggregates crowd-sourced knowledge., YouTube aggregates user videos, G2 aggregates reviews and so on.
Even the exceptions lean on aggregation. Forbes has contributor networks while Zapier publishes integration guides and user-submitted workflows. The NIH hosts research papers from several authors.
The domains achieving universal AI presence are structured to aggregate millions of contributions from millions of users across millions of topics.
You can’t build the next Reddit. Neither can I. That ship sailed 15 years ago (and required venture funding and a tolerance for chaos that most businesses don’t have).
But—and this is the important part—you can optimize your presence on Reddit. And Wikipedia. And LinkedIn.
Finding #2: The citation gap is massive (and it tells us what LLMs trust)
The average citations by platform strategy:
- Universal domains (5-8 platforms): 1,456 citations
- Multi-platform domains (2-4): 55 citations
- Single-platform domains (1): 8 citations
Universal domains get cited 26 times more than multi-platform domains and 182 times more than single-platform domains.
This is yet another data point showing us that LLMs heavily favor user-generated content and community wisdom when answering queries, especially decision-oriented ones. These sites are structured to provide the exact format of information LLMs trust: community-vetted, multi-perspective, experiential content.
This aligns with what we already knew from the school of SEO: third-party signals are important. In the AI era, “off-page” just takes on renewed importance. You need to have a consistent, ironclad presence on the third-party platforms AI systems already perceive as aggregators of truth.
Finding #3: URL diversification is a structural outcome of UGC
One of the clearest patterns separating universal domains from everyone else is that they have tens of thousands—sometimes hundreds of thousands—of unique URLs getting cited.
- Reddit: 678,255 unique URLs cited in our dataset
- Wikipedia: 111,823 unique URLs
- YouTube: 366,197 unique URLs
- LinkedIn: 205,055 unique URLs
Compare that to domains with over-concentrated citations (where 70%+ of citations go to a single URL):
- Average unique URLs: 1
- Average total citations: 1
- Platform presence: 1 platform
Not surprising.
Reddit has 678,255 URLs because it has millions of users creating posts and comments every day across tens of thousands of subreddits. That diversity emerges from the inherent structure of the platform.
Wikipedia has 111,823 URLs because it documents everything and relies on global contributors. YouTube has 366,197 because millions of creators upload videos.
These platforms win on diversification because they’re designed to aggregate. Every new user, post and video is a new potential citation target.
You’re not going to publish 678,000 pages (and if you tried, most of them would be low-quality filler). But you can create strategic content on these platforms:
- A well-optimized Reddit comment thread in a relevant subreddit
- A detailed Wikipedia page
- A YouTube video addressing common questions in your space
- A LinkedIn article establishing thought leadership.
Your focus isn’t to match UGC platforms on volume, but rather place high-value content where LLMs are already looking.
Finding #4: Query frames have distinct winners (and some are more monopolized than others)
Along with platform presence and URL diversity, there’s another dimension worth examining: which domains take over specific query types.
We tracked seven primary query frames based on how people ask questions:
- Alternatives: “[Brand/product] alternatives”
- Comparison: “[X] vs [Y]”
- How-to: “How to [action]”
- List/Best: “Best [category]”
- Pricing: “How much does [X] cost”
- Troubleshooting: “[Problem] not working”
- What is: “What is [term]”
For each frame, we looked at which domains get cited most often and whether those citations cluster around specific players or distribute more evenly.
The pattern is stark. Some query frames are monopolized, while others are wide open:
- Alternatives queries: Reddit
- “What is” queries: Wikipedia
- How-to queries: YouTube + Stack Overflow (split by technical depth)
- Comparison queries: G2 and Capterra (B2B) / CNET and TechRadar (consumer)
- Pricing queries: Less concentrated – G2/Capterra lead B2B but distribution is wider
- Troubleshooting: Stack Overflow (technical) / Reddit (consumer)
- List/Best queries: More distributed, still UGC-heavy
Reddit’s dominance in alternatives queries is particularly interesting, though not surprising. People asking for alternatives want real user experiences and Reddit delivers—as far as LLMs are concerned, better even than G2.
This pattern repeats across frames:
- “What is” queries want encyclopedic definitions → Wikipedia wins
- How-to queries want step-by-step instructions → YouTube and Stack Overflow win
- Comparison queries want feature-by-feature analysis → Review platforms win
The strategic implications for GEO
It’s not news that you need to care about more than just your owned channels to succeed in AI search. But the sheer magnitude probably is.
Universal domains get cited 182 times more than single-platform domains. And those universal domains are almost exclusively UGC aggregators: Reddit, Wikipedia, YouTube, LinkedIn, Medium.
This isn’t a sign to abandon owned content. It’s telling you that third-party presence is where the bulk of citation volume lives and treating it as a nice-to-have instead of a strategic imperative means you’re ignoring where a lot of the game is being played.
You need both a really good foundation of owned content and really good third-party hygiene.
Your owned content establishes what you do and how you do it from your POV. Product pages, documentation, blog posts and case studies are the structure. But LLMs don’t just pull from your site when someone asks about your category. They pull from Reddit threads comparing tools in your space, G2 ratings, third-party listicles and on and on it goes.
Even when those third-party mentions don’t get directly cited, models are pulling information from them to form their understanding of your brand. When they recommend you in certain contexts or position you against competitors, they’re drawing on everything that’s out there about you, not just what you publish.
You can’t control every mention, but you can influence the narrative through judicious presence on UGC platforms, engagement with review sites, partnerships with publishers and monitoring what’s being said in spaces where your audience is active.
That’s where the citations are. That’s where the broader information ecosystem that forms brand understanding lives.
Methodology
Data collection period: May 2025 to October 2025
Platforms tracked: ChatGPT Plus, ChatGPT Pro, Claude 4 with search, Perplexity (free tier), Gemini, Gemini with search, Google AI Mode, Grok, and Copilot.
Citation logging: We tracked every domain cited in AI responses, including URL-level granularity, query metadata, and timestamp data. Any domain appearing at least once during the study period was included in the dataset (n=2,384,921).
Due to dataset size, we analyzed summary statistics across all 2.4M domains and pulled detailed examples from the top 1,000 performers in each category. For consistency and URL diversity analyses, we filtered to domains with at least 100 citations to focus on meaningful patterns rather than outliers. For frame analysis, we examined the top 50 domains per frame type.
Content Marketer
Mariana is a creator and strategist making ICPs, CEOs, SERPs, LLMs (and many other acronyms) happy all at once. Over the past seven years, she's designed, deployed and scaled content programs that deliver measurable growth for B2B and B2C brands alike.
Quality-first (always), AI-curious (not AI-dependent) and just the right amount of stubborn about what makes content worth reading.




